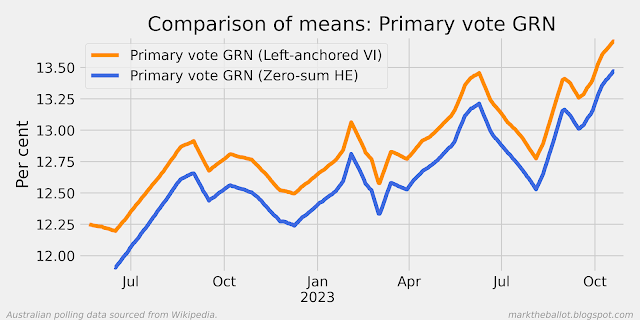
I have coded Bayesian aggregations of the polls for the 2025 Federal election. A key assumption in that aggregation model is that the polls are on average unbiased. While an individual pollsters may have a house effect, collectively I have assumed these house effects sum to zero.
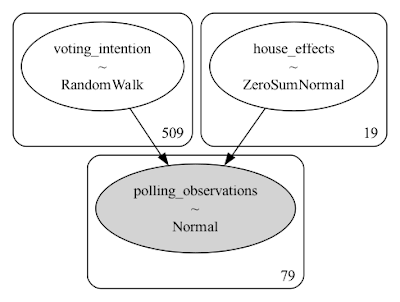
Another way of looking at the polls is to anchor the model for daily voting intention to the result at the previous election. Under this approach, I assume that there is a collective polling error, and the model allows us to determine the size of that polling error. The model is as follows:

The results for the two party preferred ALP voting intention are as follows.




We can see that on average, if we anchor our model of day-to-day voting intention to the result on election day in May 2022, that our estimate is 1.3 percentage points less favourable to Labor. However, while the polls appear to have a pro-Labor bias, we need to be cautious. Partly because the model is less constrained than the previous model, and partly because there are few polls on the left hand side, the confidence intervals associated with the model are wider than for our zero-sum house effects model. In particular, the model results suggest that the systemic poll error might be anywhere between -1.0 and +3.5 percentage points in Labour's favour. Therefore, while it is more likely than not that the two-party preferred (2pp) polls favour Labor, with these results we cannot be certain.
The only series where the model is certain that the polls collectively are biased is in respect of Labor's primary vote shares, where the polls appear to be 2.7 percentage points collectively more favourable to Labor. We can be confident as the associated probability density chart below does not have zero within the highest density interval (HDI). While we cannot be certain, it does look like it is more likely than not that some bias is also evident with the Coalition and Other parties primary vote share.